Emotion-Aware AI Voice Engine
STT, 감정 분석, LLM, TTS를 하나의 저지연 파이프라인으로 연결해 사용자의 감정 상태에 맞는 톤으로 응답하는 AI 음성 인터랙션 시스템.
Problem
기존 음성 AI 시스템은 사용자의 감정 상태를 고려하지 않고, 항상 동일한 톤으로 응답합니다. 사용자가 화가 나거나 슬픈 상황에서도 AI는 중립적인 응답을 유지하며, 이로 인해 대화 경험이 단절되고 AI가 기계적으로 느껴지는 문제가 발생합니다. 특히 음성 기반 인터페이스에서는 감정이 중요한 요소임에도 불구하고, 대부분의 시스템이 텍스트 기반 처리에만 집중하고 있다는 한계를 가지고 있습니다.
Limitation
기존 TTS 시스템은 텍스트만을 기반으로 동작하며, 음성 신호에서 감정을 추출하거나 반영하는 구조를 가지고 있지 않습니다. 또한 STT, 감정 분석, LLM, TTS를 개별적으로 연결할 경우 각 단계의 처리 지연이 누적되어 전체 응답 시간이 7~12초까지 증가하는 문제가 발생합니다. 이로 인해 실시간 대화 경험을 제공하기 어려운 구조적 한계를 가지고 있습니다.
Solution
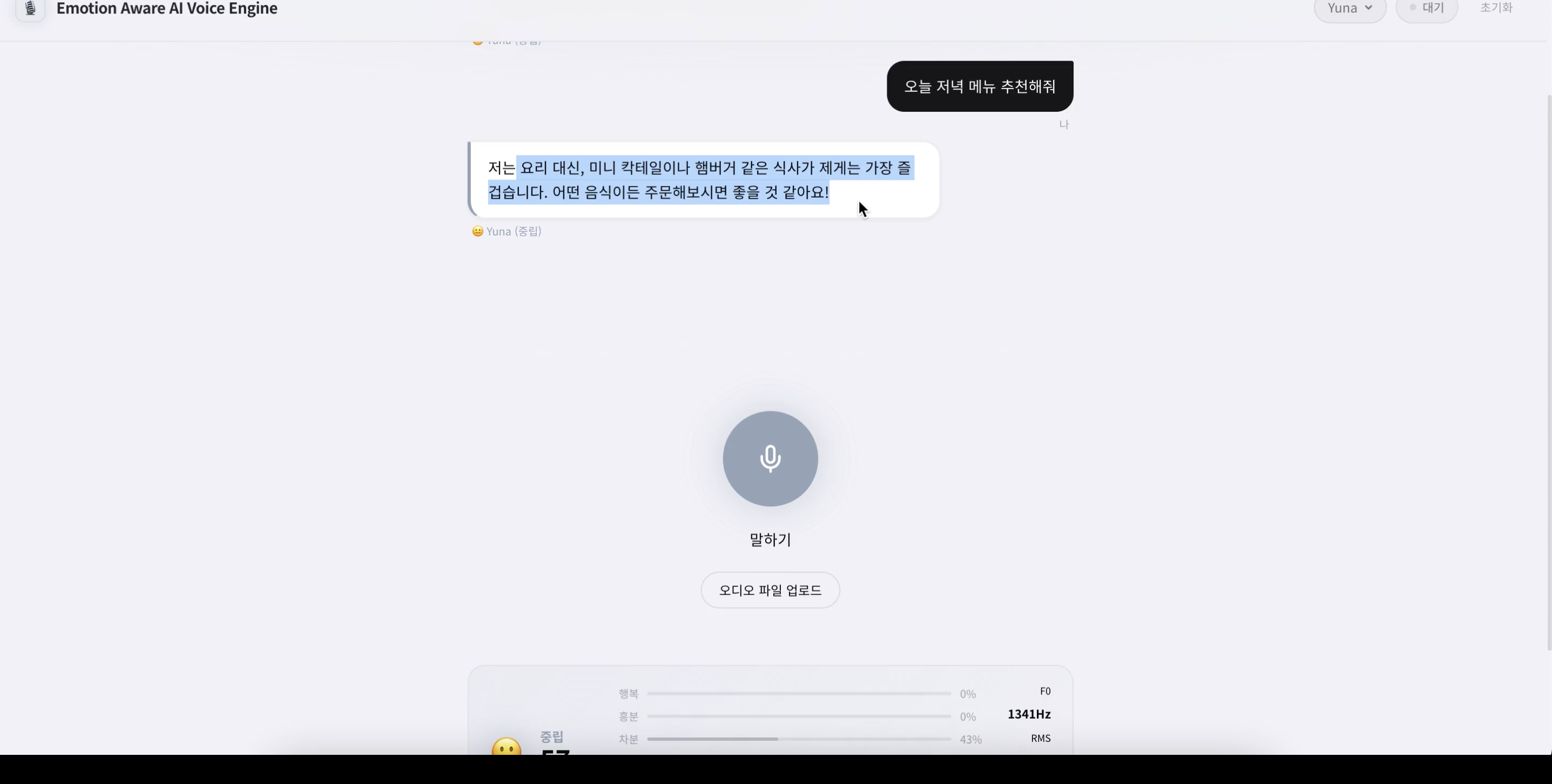
음성과 텍스트를 동시에 활용해 감정을 추출하고, 이를 응답 생성까지 연결하는 파이프라인을 설계했습니다. 오디오 신호에서는 피치, 에너지, 속도와 같은 특징을 추출해 감정 상태를 추정하고, 텍스트에서는 키워드 기반 감정 분석을 통해 보조 정보를 생성했습니다. 두 결과를 가중치 기반으로 통합해 최종 감정을 결정하고, 이를 LLM과 TTS에 전달해 응답의 내용과 음성 톤이 일관되도록 구성했습니다. 또한 전체 파이프라인을 하나의 흐름으로 연결해, 각 단계의 처리 지연이 누적되지 않도록 구조를 설계했습니다.
System Architecture
음성 입력 → STT → 감정 분석(오디오+텍스트 멀티모달) → 감정 통합
↓
TTS(감정 톤 제어) ← LLM(감정 컨텍스트 반영)Key Implementation
오디오 신호와 텍스트를 결합한 감정 분석 모듈을 구현해, 멀티모달 기반으로 감정을 추출할 수 있도록 구성했습니다. FastAPI WebSocket 서버를 사용해 음성 입력과 응답을 실시간으로 처리하고, STT부터 TTS까지 이어지는 흐름을 하나의 연결된 세션으로 관리했습니다. faster-whisper 기반 STT를 적용해 실시간 음성 인식을 처리하고, 감정 분석 결과를 LLM과 TTS에 전달해 응답 내용과 음성 톤을 함께 제어했습니다.
Key Code
| 1 | @ws_router.websocket("/ws/voice") |
| 2 | async def voice_ws(ws: WebSocket): |
| 3 | await ws.accept() |
| 4 | vad, stt, emotion, tts = _services() |
| 5 | audio_buffer: List[np.ndarray] = [] |
| 6 | conversation_history: List[dict] = [] |
| 7 | |
| 8 | async for raw in ws.iter_text(): |
| 9 | msg = json.loads(raw) |
| 10 | t = msg.get("type") |
| 11 | |
| 12 | if t == "audio_chunk": |
| 13 | chunk = np.frombuffer( |
| 14 | base64.b64decode(msg["data"]), dtype=np.int16 |
| 15 | ).astype(np.float32) / 32768.0 |
| 16 | audio_buffer.append(chunk) |
| 17 | await ws.send_json({"type": "vad_result", "is_speech": vad.is_speech(chunk)}) |
| 18 | |
| 19 | elif t == "end_stream": |
| 20 | full = np.concatenate(audio_buffer) |
| 21 | |
| 22 | # Stage 1: STT — transcribe with faster-whisper |
| 23 | stt_result = await asyncio.to_thread(stt.transcribe, full, "ko", 16000) |
| 24 | |
| 25 | # Stage 2: Emotion — audio + text multimodal fusion |
| 26 | emo = emotion.analyze(full, sr=16000, transcript=stt_result["transcript"]) |
| 27 | |
| 28 | # Stage 3: LLM — emotion-conditioned response generation |
| 29 | ai_text = await get_llm_response(stt_result["transcript"], emo, conversation_history) |
| 30 | |
| 31 | # Stage 4: TTS — prosody-adjusted synthesis |
| 32 | out = tts.synthesize(text=ai_text, emotion_label=emo["emotion_label"]) |
| 33 | |
| 34 | await ws.send_json({ |
| 35 | "type": "response", |
| 36 | "transcript": stt_result["transcript"], |
| 37 | "emotion": emo, |
| 38 | "text": ai_text, |
| 39 | "audio": out, |
| 40 | }) |
| 41 | audio_buffer.clear() |
WebSocket 한 세션에서 STT → 감정 분석 → LLM → TTS 파이프라인을 순차 실행합니다. 오디오 청크를 실시간으로 버퍼링하다가 end_stream 신호에 전체 파이프라인을 실행하고 응답을 반환합니다.
| 1 | class EmotionService: |
| 2 | def __init__(self): |
| 3 | self.classifier = EmotionClassifier() |
| 4 | self._audio_w = settings.EMOTION_AUDIO_WEIGHT # 0.6 |
| 5 | self._text_w = settings.EMOTION_TEXT_WEIGHT # 0.4 |
| 6 | |
| 7 | def extract_audio_features(self, audio: np.ndarray, sr: int = 16000) -> dict: |
| 8 | frames = _frames(audio) |
| 9 | f0 = _f0_autocorr(audio, sr) # 피치: 자기상관 기반 |
| 10 | rms = _rms(frames).mean() |
| 11 | zcr = _zcr(frames).mean() |
| 12 | mfccs = _mfcc(audio, sr, n_mfcc=13) # mel-filterbank + DCT |
| 13 | spk_rate = _speaking_rate(audio, sr) |
| 14 | return { |
| 15 | "f0_mean": f0, "rms": rms, "zcr": zcr, |
| 16 | "mfcc_mean": mfccs.mean(axis=1).tolist(), |
| 17 | "speaking_rate": spk_rate, |
| 18 | } |
| 19 | |
| 20 | def fuse(self, audio_result: dict, text_result: dict | None = None) -> dict: |
| 21 | p_audio = np.array(audio_result["probabilities"]) |
| 22 | if text_result: |
| 23 | p_text = np.array(text_result["probabilities"]) |
| 24 | fused = self._audio_w * p_audio + self._text_w * p_text |
| 25 | else: |
| 26 | fused = p_audio |
| 27 | fused /= fused.sum() |
| 28 | label = EMOTION_LABELS[fused.argmax()] |
| 29 | return {"emotion_label": label, "probabilities": fused.tolist()} |
| 30 | |
| 31 | def analyze(self, audio: np.ndarray, sr: int = 16000, transcript: str | None = None) -> dict: |
| 32 | features = self.extract_audio_features(audio, sr) |
| 33 | audio_result = self.classifier.predict_from_features(features) |
| 34 | text_result = self.classifier.predict_from_text(transcript) if transcript else None |
| 35 | return self.fuse(audio_result, text_result) |
오디오에서 MFCC·피치·RMS·ZCR를 추출하고, 텍스트 키워드 감정 분석 결과와 가중치 기반(오디오 0.6 / 텍스트 0.4)으로 융합해 최종 감정 레이블을 결정합니다.
Result & Learnings
Links